![[論文] SIGMOD/PODS 2024 Amazon Redshiftにおけるクエリ実行時間予測システム「Stage predictor」](https://devio2024-media.developers.io/image/upload/f_auto,q_auto,w_3840/v1729435611/user-gen-eyecatch/k2u8vqohn8u49xo25lqs.jpg)
[論文] SIGMOD/PODS 2024 Amazon Redshiftにおけるクエリ実行時間予測システム「Stage predictor」
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。SIGMOD/PODS 2024にて、Amazon Redshiftにおける新しいクエリ実行時間予測システム「Stage predictor」について発表しました。この技術を論文をベースに解説します。
Stage: Query execution time prediction in Amazon Redshift
この論文では、Amazon Redshiftのクエリ実行時間予測のための新しい階層的予測モデル「Stage predictor」を提案しています。このモデルは、実行時間キャッシュ、特定のDBインスタンス用に最適化された軽量ローカルモデル、そしてRedshift全体で転用可能な複雑なグローバルモデルの3つの状態で構成されています。Stage predictorはより正確で堅牢な予測を実用的な推論遅延とメモリオーバーヘッドで改善できました。
ABSTRACT
Amazon Redshiftは、クエリ実行時間の正確な予測に依存していますが、既存の予測技術には課題がありました。そこで、Redshiftの特性を活かした階層的な実行時間予測器「Stage predictor」が提案されました。これは、実行時間キャッシュ、軽量なローカルモデル、複雑なグローバルモデルの3つの状態で構成されています。実験結果では、Stage predictorがより正確で堅牢な予測を行い、実用的な推論遅延とメモリオーバーヘッドを維持しながら、平均クエリ実行遅延を20%改善できることが示されました。
1 INTRODUCTION
クラウドDBMSにおいて、クエリの実行時間を予測することは非常に重要です。Amazon Redshiftは、この予測を様々なタスクに活用していますが、既存の予測モデル(AutoWLM)にはいくつかの課題がありました。そこで、新しい階層的実行時間予測モデル(Stage)が開発されました。
Stageは3つの段階で構成されています。まず、最近実行されたクエリの実行時間をキャッシュし、同一クエリが再度実行される際にその時間を予測します。次に、軽量なローカルモデルが不確実性を測定しながら予測します。最後に、複雑なグローバルモデルが全インスタンスにわたって転移可能な予測を提供します。
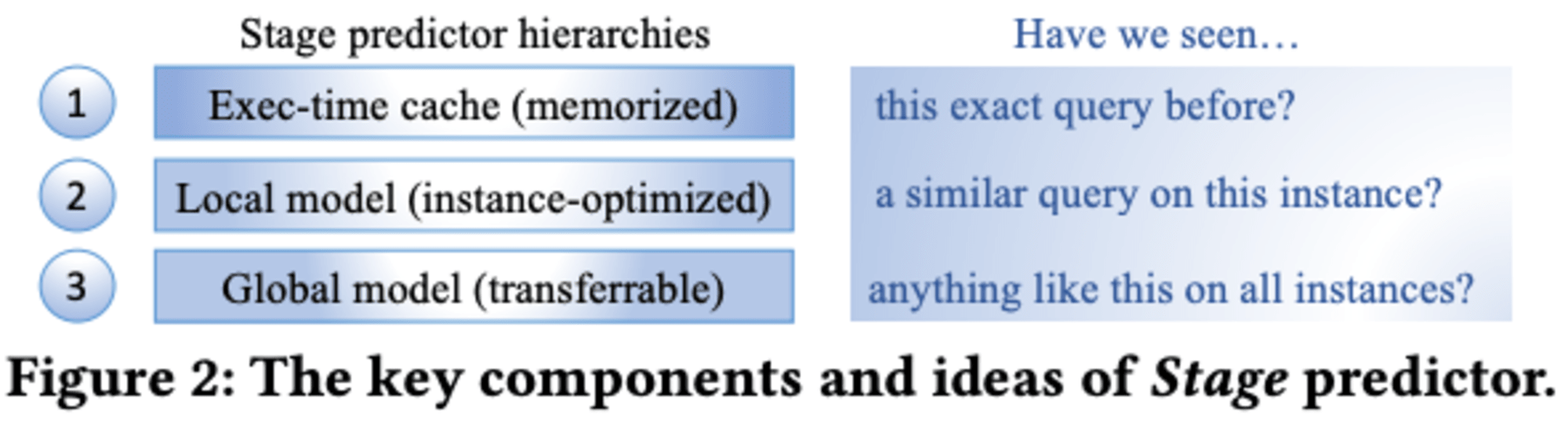
この階層的アプローチにより、Stageはコールドスタート時の予測、推論時間、信頼性の高い推定という課題に対処しています。ローカルモデルは軽量なXGBoostモデルのベイジアンアンサンブルを使用し、グローバルモデルはグラフニューラルネットワークを採用しています。
Amazon Redshiftの実際の本番環境でStageをシミュレーションした結果、従来の予測モデルと比較して平均クエリ実行時間を20%改善しました。Stageは、高価な機械学習モデルを顧客向けの本番システムのクリティカルパスに実用的に統合する方法を示しています。
この新しいアプローチは、クエリの実行時間予測において階層的なモデルの概念を適用した初めての試みであり、クラウドデータベース管理システムの性能向上に大きく貢献する可能性があります。
著者補足
XGBoostモデルのベイジアンアンサンブルは、複数のXGBoostモデルを組み合わせ、ベイズ最適化を用いてハイパーパラメータを調整する手法です。この方法では、各モデルの予測を統合し、より高精度で汎化性能の高い予測を実現します。ベイズ最適化により、効率的にモデルのパフォーマンスを向上させ、過学習を抑制しつつ予測精度を高めることができます。
**グラフニューラルネットワーク(GNN)**は、グラフ構造を持つデータを処理するための深層学習モデルです。ノードとエッジから成るグラフデータに対し、各ノードの特徴を周囲のノードの情報を集約して更新することで、グラフ全体の構造や関係性を学習します。これにより、ソーシャルネットワーク分析や分子構造予測など、複雑な関係性を持つデータの処理に適しています.
2 BACKGROUND
2.1 Execution time predictor in Redshift
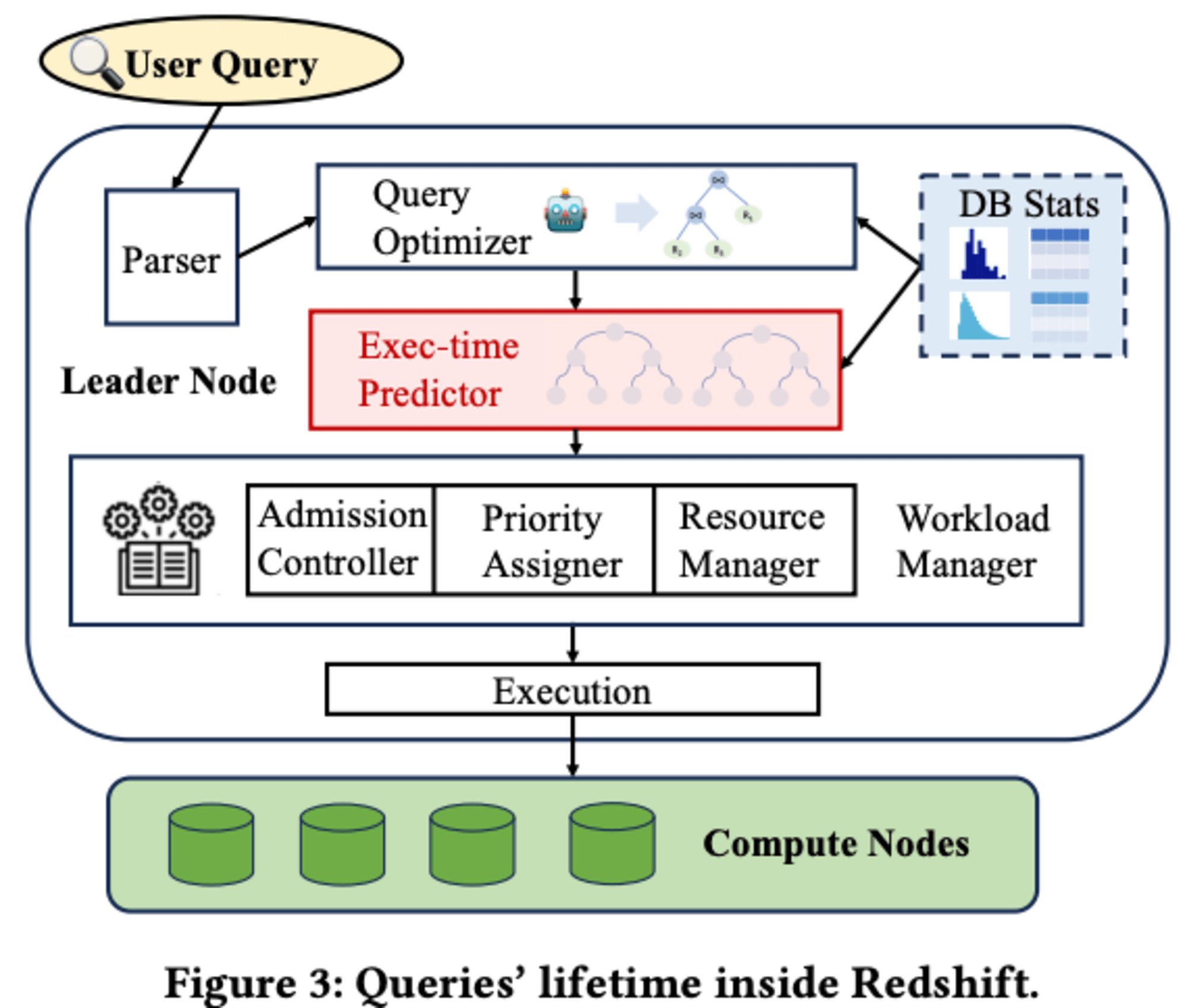
Redshiftにおけるクエリの処理フローは、パーサーとクエリオプティマイザを経て物理実行プランが作成され、その後実行時間予測器によって実行時間が予測されます。この予測に基づき、ワークロードマネージャーがクエリの実行戦略とリソース割り当てを決定します。実行時間予測は、クエリの優先順位付けや並行スケーリングクラスターの最適なサイズ選択など、重要な意思決定に使用されます。
現在のAutoWLM Predictorは、軽量なXGBoostモデルを使用していますが、簡素化された機能化技術のため、時に不正確な予測を生み出すことがあります。また、新しいインスタンスでのコールドスタート問題や、下流タスクに必要な信頼区間の提供にも課題があります。
実行時間予測の精度は、クエリのパフォーマンスに直接影響を与えます。不正確な予測は、長時間実行クエリを短時間実行と誤認し、他の短時間クエリをブロックしてしまう可能性があります。逆に、短時間クエリを長時間実行と誤認すると、実行前に長時間待機する可能性があります。
2.2 Related Works
不確実性の定量化とクエリ性能予測に関する先行研究について概観しています。
XGBoostモデルは、幅広いタスクで最先端の性能を達成するスケーラブルな勾配ブースティングツリーモデルです。最近の研究では、ベイズアンサンブルを用いてモデル予測の不確実性を推定する手法が提案されています。この手法では、モデル不確実性とデータ不確実性に分け、XGBoostモデルを確率的損失関数で訓練し、平均と分散を出力します。ベイズアンサンブルは複数のXGBoostモデルを独立に訓練し、総合的な不確実性を求めます。
一方、従来の実行時間予測は手作業のヒューリスティックや統計モデルを使用していましたが、機械学習モデルがより高精度な予測を可能にしています。しかし、これらの方法は推論遅延が大きく、Redshiftのようなシステムでは実行時間が短いクエリには適しません。
ゼロショット予測器は、多様なデータベースインスタンスで訓練された1つのモデルを用い、新しいインスタンスでも即座に予測可能です。
さらに、機械学習はデータベースシステムの最適化や管理にも大きな影響を与えており、ワークロード管理やインデックス推奨、設定調整などに役立っています。
3 DESIGN PRINCIPLES
Redshiftのクエリ予測機能は、3つの重要な設計原則に基づいています。まず、多くのクエリが繰り返し実行されるため、この反復性を活用することが重要です。次に、単なる平均予測では不十分で、各予測に合理的な信頼区間が必要です。最後に、多くのクエリが数ミリ秒で実行されるため、推論時間をマイクロ秒単位に抑える必要があります。
これらの原則に基づき、Redshiftの予測機能は以下のように設計されています。繰り返しクエリに対応するため、過去のパフォーマンスを活用する**「キャッシング」ステージを導入**しています。高信頼性の予測を実現するため、エラー範囲を考慮し、より正確な予測が必要な場合に追加の推論時間を割り当てます。低推論レイテンシを実現するため、長時間実行されると予測されるクエリに対してのみ高度なニューラルネットワークモデルを使用します。
この設計により、Redshiftは多様なクエリに対して効率的かつ正確な実行時間予測を提供し、クエリスケジューリングやクラスターサイジングなどのダウンストリームタスクを最適化しています。
4 STAGE PREDICTOR
Redshiftの特定のニーズに対応するため、Stage exec-time predictorは段階的に動作するよう設計されています。最初の段階では最近実行されたクエリを記憶し、一致するものがあれば予測します。一致しない場合は、ユーザーのクラスターごとに最適化されたローカルモデルに進みます。さらに予測が困難な場合は、Redshift全体で訓練された最先端のグラフ畳み込みニューラルネットワークであるグローバルモデルが使用されます。
著者補足
**グラフ畳み込みニューラルネットワーク(Graph Convolutional Neural Networks、GCN)**は、グラフ構造を持つデータに対して深層学習を適用するための手法です。従来の畳み込みニューラルネットワーク(CNN)が画像などの格子状データに効果的であるのに対し、GCNはソーシャルネットワーク、分子構造、交通ネットワークなどの非格子状の複雑なグラフデータを扱うことができます。
4.1 Overview
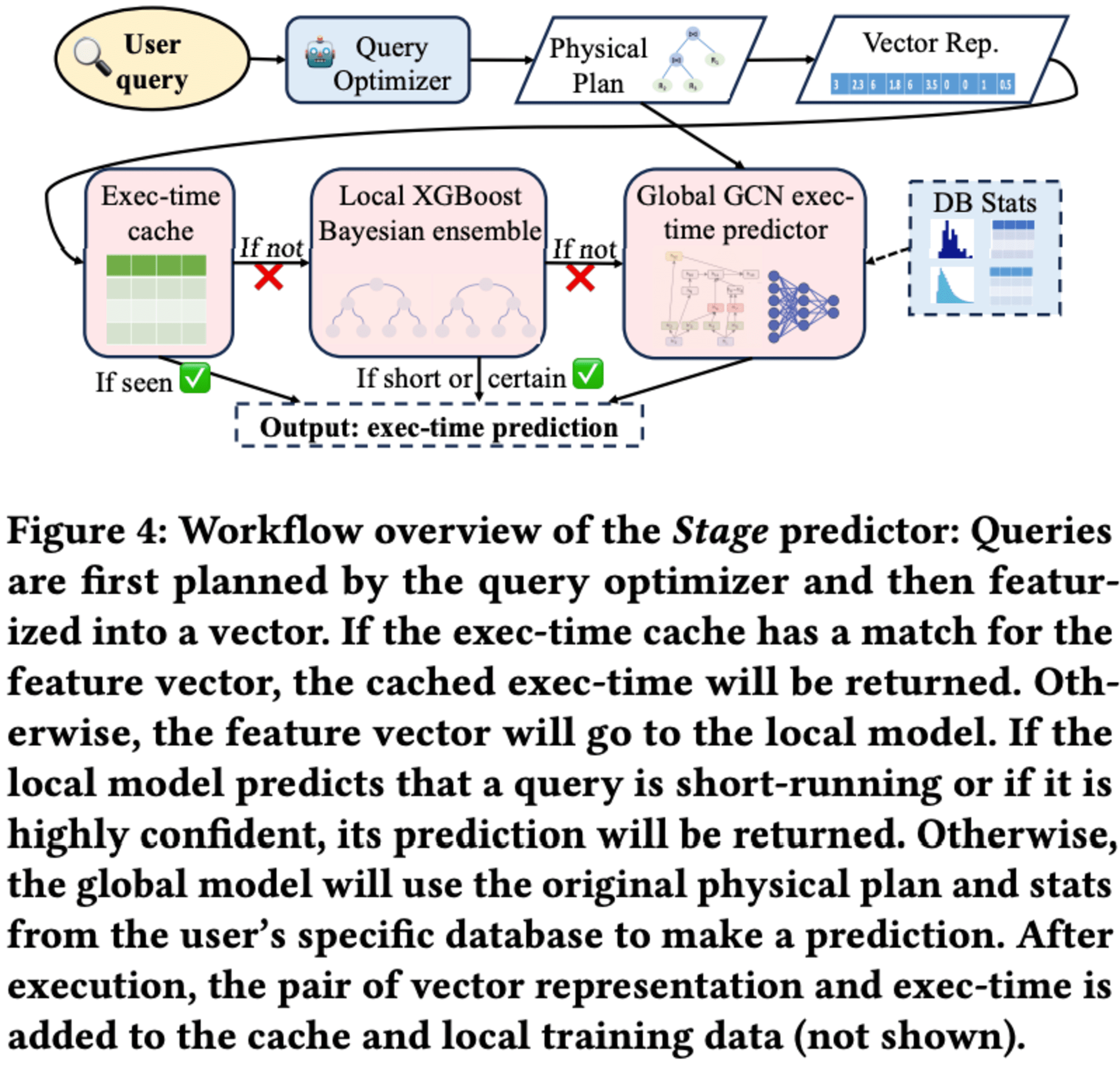
Stage predictorは、ユーザーのクエリの実行時間を予測する高度なシステムです。このシステムは、クエリの物理的実行プランを33次元のベクトルに変換し、まず実行時間キャッシュをチェックします。キャッシュにヒットしない場合、ローカルモデルが予測します。ローカルモデルが短時間実行と判断するか、高い確信度を持つ場合、その予測が採用されます。
しかし、ローカルモデルが不確実な場合、グローバルモデルが使用されます。グローバルモデルは、クエリの物理プランを入力として受け取り、オペレーターノード間の複雑な相互作用を理解します。このモデルは、多様なインスタンスからの実行済みクエリで訓練され、Amazon Redshiftのフリート全体で共有されています。
Stage predictorの利点は、実行時間キャッシュの最適性、ローカルモデルのインスタンス最適化、グローバルモデルの転移可能なナレッジを組み合わせることで、高い予測精度と低い推論レイテンシーを実現していることです。また、新しいインスタンスや変化するデータ・クエリワークロードに対しても信頼性の高いパフォーマンスを提供します。さらに、予測実行時間の確率分布や信頼区間を提供することで、多くのダウンストリームタスクの堅牢な意思決定を可能にします。
4.2 Exec-time Cache
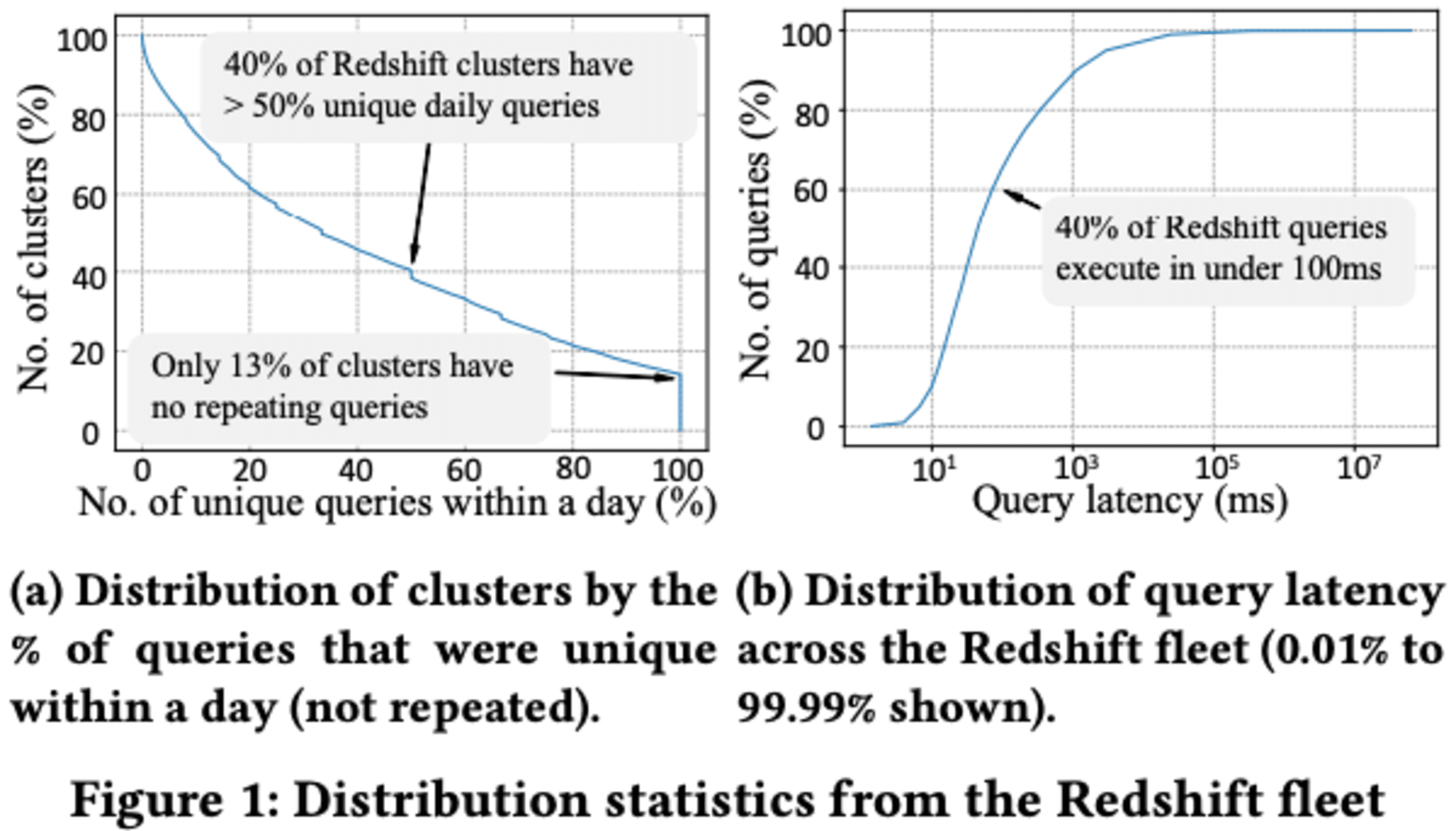
エグゼクティブタイムキャッシュは、最近観測された繰り返しクエリに対して、ほぼゼロの推論遅延で最適に近い予測を出力できます。これは、Redshiftフリート全体で平均60%のクエリに該当します。
キャッシュのキーは、物理プランツリーを平坦化したベクトル表現を使用し、値には実際の実行時間を格納します。予測時には、過去の観測値の平均と最新の観測値を組み合わせたヒューリスティックを用いて、データの堅牢性と鮮度の両方を捉えます。
キャッシュが一定のしきい値を超えた場合、最も更新されていないクエリを削除する方針を採用しています。これにより、効率的なメモリ使用と高速な検索速度を維持しています。
最適化として、クエリ特徴ベクトルのハッシュ値をキーとして使用することで、ベクトル間の比較を省略し、ハッシュテーブルのキーサイズを大幅に削減しています。また、過去のクエリ遅延のリストの代わりに、実行時間の実行平均と分散を格納することで、キャッシュのメモリサイズと検索時間を削減しています。
このエグゼクティブタイムキャッシュは、新しいインスタンスや変化するデータとクエリワークロードを持つインスタンスでも信頼性の高いパフォーマンスを発揮します。さらに、予測された実行時間の確率分布や信頼区間を提供することで、多くのダウンストリームタスクの堅牢な意思決定を可能にしています。
4.3 Instance-optimized local model
Redshiftのローカルモデルは、XGBoostモデルのベイジアンアンサンブルを採用しています。このモデルは、クエリの33次元ベクトル表現を入力とし、実行時間の平均と分散を推定します。最終的な予測は、各モデルの予測の平均として算出され、その不確実性は、モデルの不確実性とデータの不確実性の合計として計算されます。
この設計は、モデルの不確実性とデータの不確実性の両方を捉えることができる点で優れています。モデルの不確実性は、訓練データが不十分な場合や新しいタイプのクエリに対して高くなります。一方、データの不確実性は、システム負荷の変動やクエリプランの複雑さによる予測の難しさを反映します。
他の機械学習手法と比較して、このアプローチはRedshiftの特性に適しており、実装も比較的容易です。深層学習モデルは推論の遅延が大きいため実用的ではなく、他の軽量な手法は通常、一方の不確実性のみに焦点を当てています。
ローカルモデルの訓練プロセスは、効果的なモデルを構築しつつ、メモリと計算のオーバーヘッドを低く抑えるように最適化されています。訓練クエリプールのサイズを制限し、重複クエリを排除し、実行時間の多様性を確保するための工夫が施されています。具体的には、実行時間キャッシュを利用して効率的にデータの重複を排除し、クエリを実行時間に基づいて複数のバケットに分割しています。
これらの設計と最適化により、Redshiftのローカルモデルはクエリの実行時間を効果的に予測し、同時に不確実性を適切に評価することができます。これにより、グローバルモデルとの連携が可能となり、より正確な予測システムが実現されています。
4.4 Transferrable global model
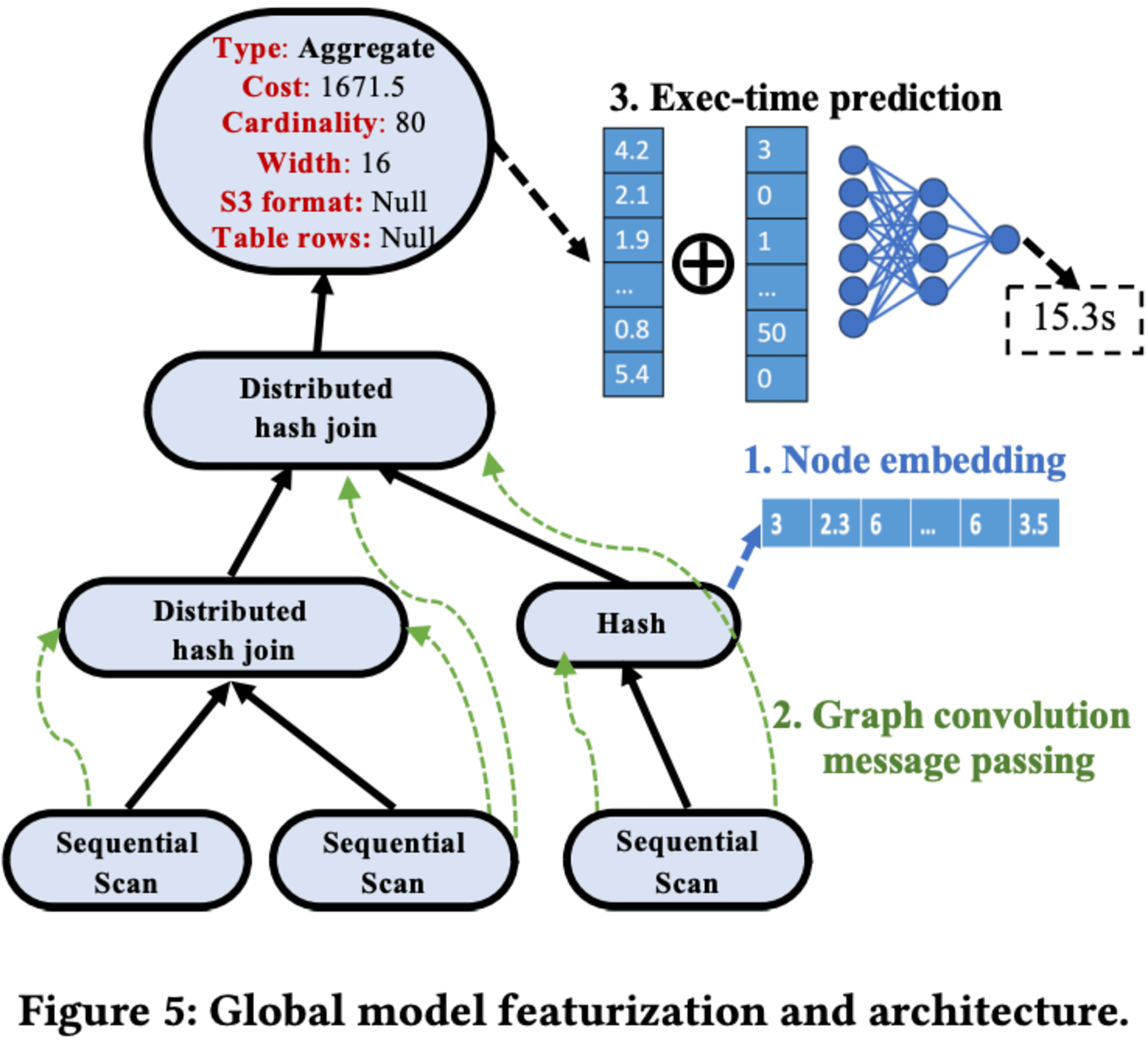
近年のゼロショットコストモデルの研究に触発され、Redshiftクエリプランのインスタンス非依存型特徴化を設計しました。これにより、様々な顧客インスタンスのクエリプランを統一された空間にマッピングすることが可能になりました。結果として、大量のRedshiftインスタンスから多様なトレーニングクエリを収集し、すべてのインスタンス(未知のインスタンスを含む)に対して堅牢な予測を行える単一のグローバルモデルを共同で訓練することができます。
このグローバルモデルは、グラフ畳み込みネットワーク(GCN)アーキテクチャを使用してRedshiftのクエリプランを理解し、実行時間にマッピングします。クエリプラン特徴化のプロセスでは、顧客のRedshiftインスタンスから実行されたクエリの物理実行プランに関するログを収集し、それらを木構造のデータ構造に解析します。各ノードは物理演算子を表し、演算子タイプ、推定コスト、推定カーディナリティ、タプル幅、S3テーブル形式、テーブル行数などの特徴を持ちます。
モデルアーキテクチャは、ノード埋め込み、グラフ畳み込みメッセージパッシング、最終実行時間予測の3つのコンポーネントで構成されています。まず、すべてのノードの特徴が多層パーセプトロン(MLP)によって特徴ベクトルに埋め込まれます。次に、GCNモデルを使用してノード間でメッセージパッシングを行い、情報を集約し、Redshiftでの演算子の相互作用を理解します。
最後に、GCNによって出力された最終ベクトル表現がシステム特徴ベクトルと連結され、MLPに送られて当該クエリの実行時間が推定されます。このグローバルGCNモデルは、各々10,000以上のクエリを持つ数百のRedshiftインスタンスの多様なセットで訓練されています。このアプローチにより、様々なRedshiftインスタンスに対して高精度な実行時間予測が可能となります。
筆者補足
データベースにおけるゼロショットコストモデルは、クエリの実行計画を最適化するための革新的なアプローチです。従来のコストモデルが大量の実行統計データを必要とするのに対し、ゼロショットコストモデルは事前の実行データなしで効果的な予測することができます。
この手法は、機械学習の分野で発展したゼロショット学習の概念をデータベース管理システムに適用したものです。ゼロショットコストモデルは、データベースのスキーマ情報、テーブルの統計、およびクエリの構造などの利用可能な情報を活用して、クエリの実行コストを予測します。これにより、新しいクエリや稀にしか実行されないクエリに対しても、適切な実行計画を選択することが可能になります。
5 EXPERIMENTAL EVALUATION
5.1 Experimental Settings
Stage predictorの性能評価は、Redshiftの実際の顧客クエリログを用いて行われました。2023年7月の上位100の最も課金されたインスタンスが3つの地域から選択され、約3000万のクエリが評価対象となりました。評価環境には、64GBメモリと16 vCPUを持つm5.4xlargeマシンが使用されました。グローバルモデルのオフライントレーニングには、より強力なp3.8xlargeマシンが使用されましたが、キャッシュやローカルモデルにはGPUは使用されていません。
モデルのトレーニングと評価は、実際のRedshiftのデプロイを模倣して行われました。クエリは記録された実行開始時間に基づいて順次再生され、グローバルモデルのトレーニングには100のトレーニングインスタンスと3週間分のユーザー実行クエリが使用されました。
Stage Predictorには、調整が比較的容易なハイパーパラメータがいくつか含まれています。実行時間キャッシュのサイズは2,000に設定され、ローカルモデルには10個のXGBoostモデルが使用されました。各XGBoostモデルのパラメータは、推定器数200、最大深度6、並列ツリー数1に設定されました。
グローバルモデルには、隠れ層の次元サイズが512、8層のグラフ畳み込み、0.2の重みドロップアウト比を持つ有向GCNが使用されました。これらのハイパーパラメータは、評価データセットとは完全に別のデータを使用して調整されました。
5.2 End-to-end Evaluation in Redshift
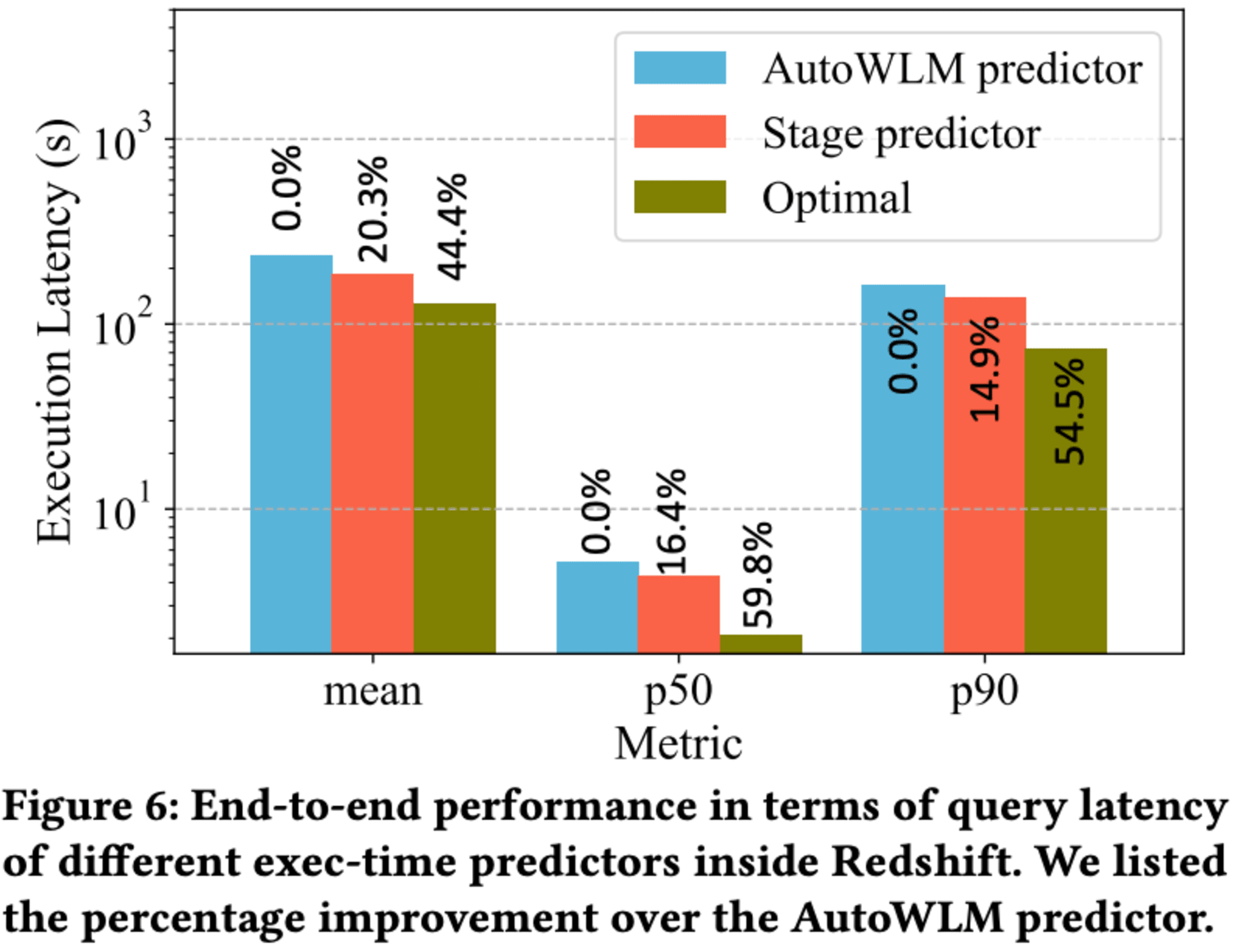
Redshiftのワークロードマネージャーにおける Stage predictor の有効性を評価するため、エンドツーエンドのクエリ実行レイテンシーに対する影響をシミュレーションで検証しました。このシミュレーションでは、既存のユーザーワークロードを再現し、Stage predictor を使用してクエリのレイテンシーを計算します。より正確な実行時間予測により、ワークロードマネージャーのスケジューリング決定が改善され、クエリのレイテンシーが向上すると考えられます。
シミュレーション結果によると、Stage predictor は AutoWLM predictor と比較して、平均で20.3%、中央値で16.4%、テールで14.9%のクエリ実行レイテンシー改善を示しました。これは、より正確な実行時間予測によるものです。しかし、理想的な予測(Optimal)と比較すると、まだ大きな改善の余地があることも明らかになりました。
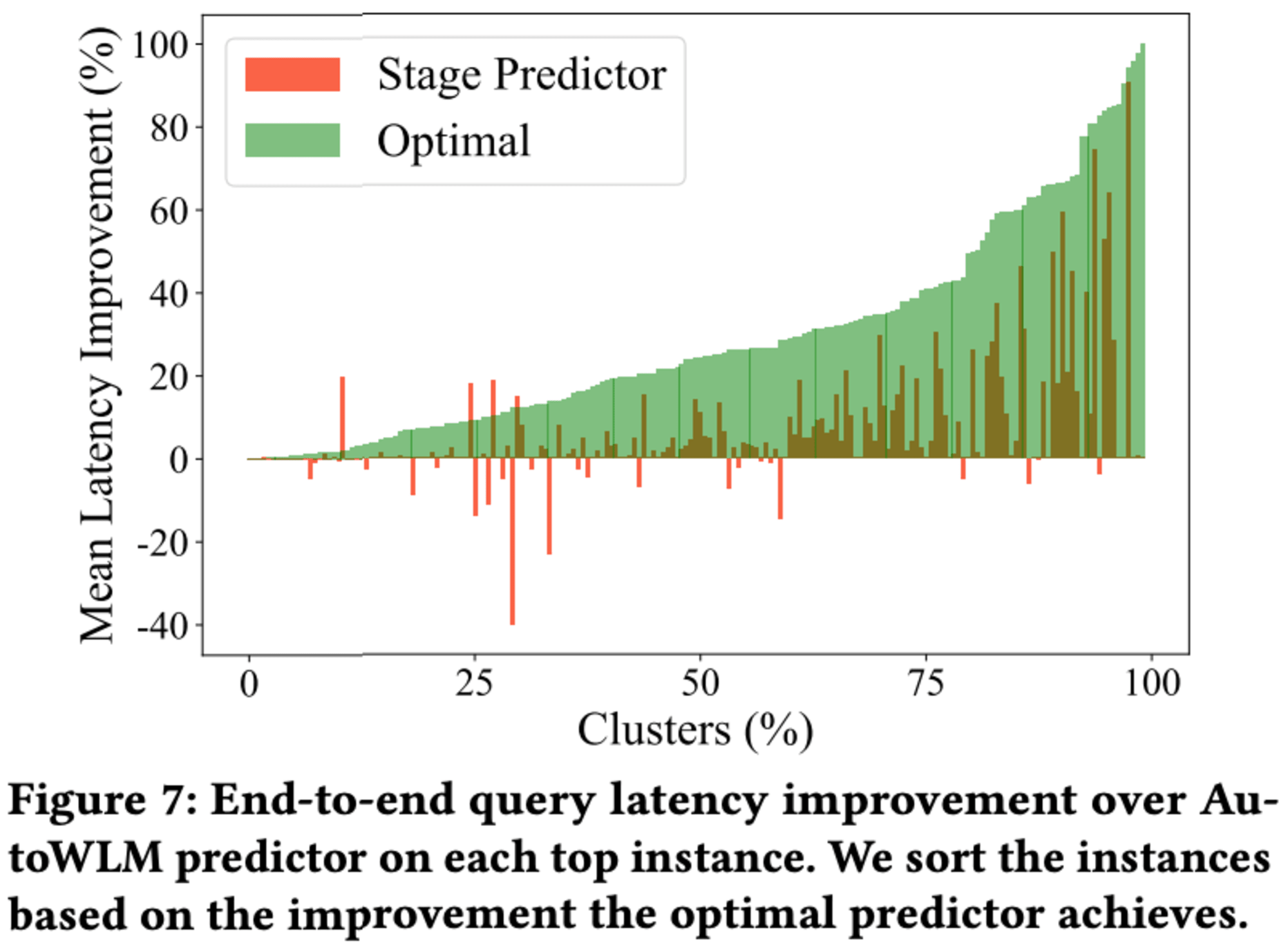
インスタンスごとの平均クエリレイテンシー改善を分析したところ、Stage predictor は大多数のインスタンスでパフォーマンスを向上させましたが、約10%のインスタンスでは AutoWLM predictor よりも悪化しました。この原因として、予測誤差の非対称性や、ワークロードマネージャーのアルゴリズム設計による特殊なケースなどが考えられます。
Stage predictor の一部(実行時間キャッシュとローカルモデル)は既に本番環境でデプロイされていますが、グローバルモデルの精度に課題があるため、より堅牢なモデルの開発を進めています。今後、Redshift における実行時間予測の精度をさらに向上させることで、クエリ実行レイテンシーの大幅な改善が期待できます。
5.3 Stage Predictor Accuracy
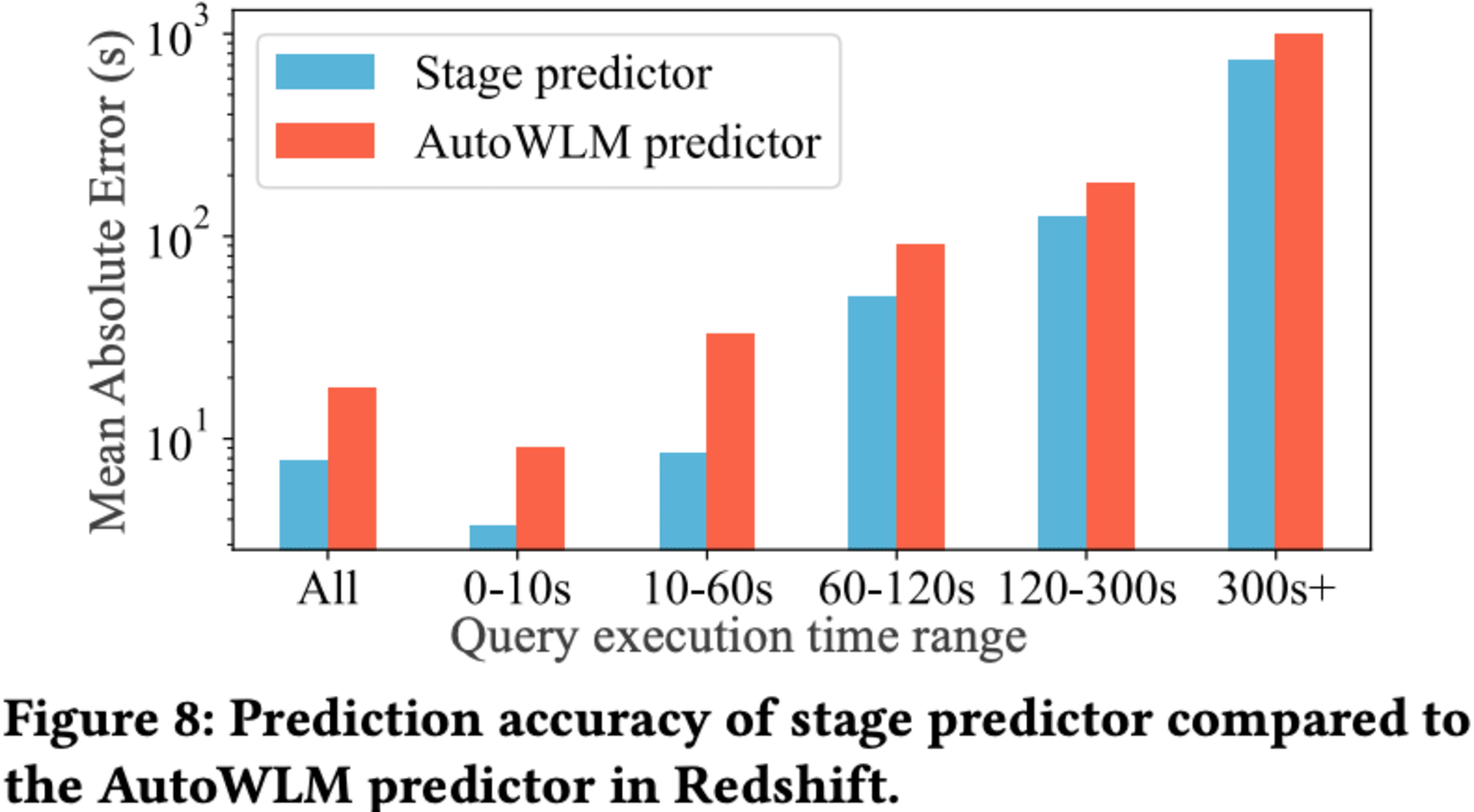
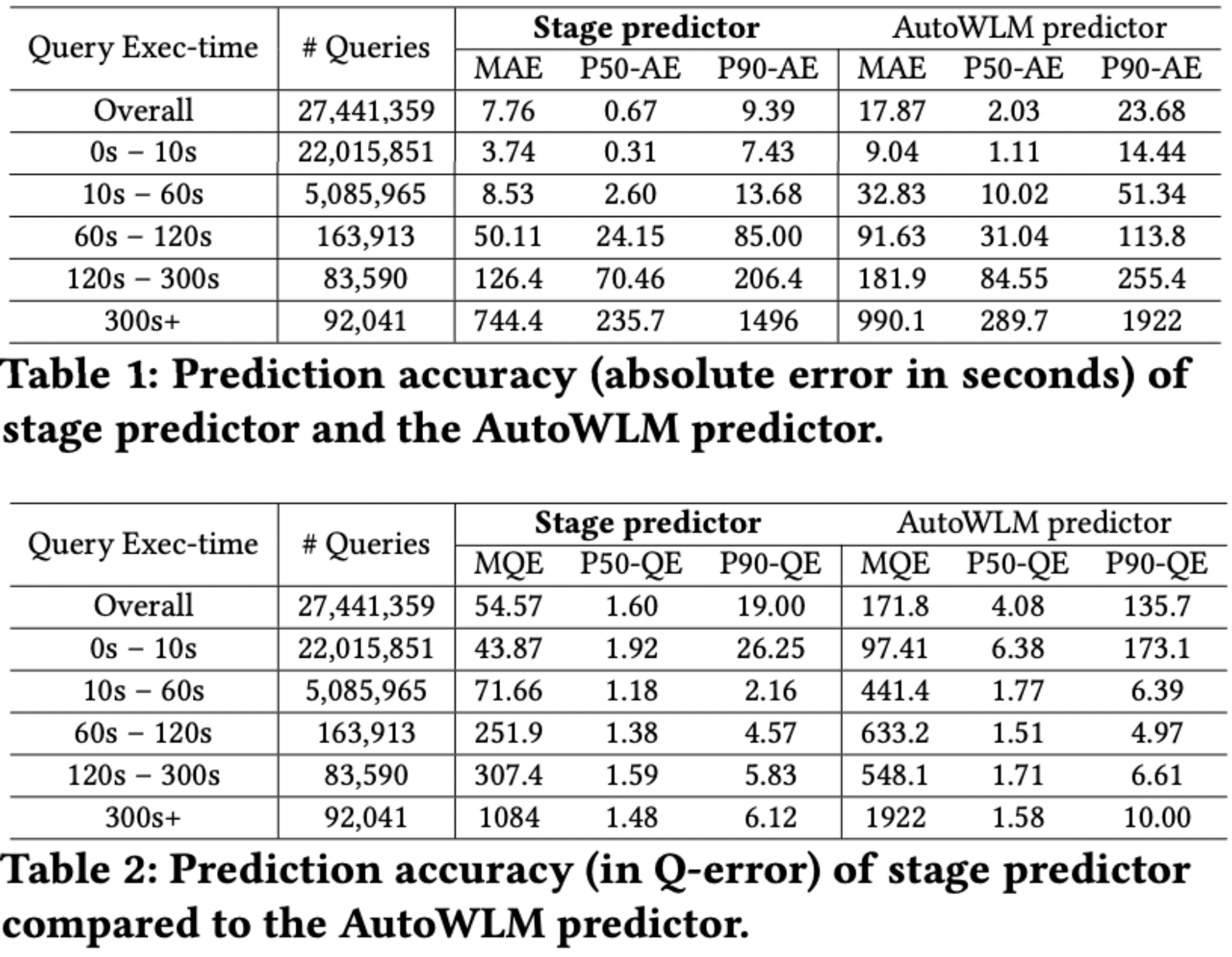
Redshiftの上位100件の最も請求額の高いインスタンスから得られた2700万以上のクエリに対して、Stage PredictorとAutoWLM Predictorの予測精度を比較した結果が示されています。絶対誤差を用いて評価したところ、Stage Predictor はAutoWLM Predictorと比べて2倍以上の精度を達成し、中央値の絶対誤差は0.67秒となりました。特に実行時間が60秒未満のクエリに対しては、3倍以上の予測精度向上が見られました。
しかし、60秒を超える長時間実行クエリに対しては、改善が限定的でした。これは、長時間実行クエリのデータが少ないことや、システム負荷やキャッシュ状態、同時実行クエリ数などの要因により、同じクエリでも実行時間に大きなばらつきが生じるためと考えられます。
推論の遅延時間とメモリ使用量のオーバーヘッドについても分析されており、Stage predictorはAutoWLM Predictorよりも大きいものの、実用的な範囲内に収まっています。具体的には、サブミリ秒の推論遅延時間と数百KBのメモリ使用量となっています。
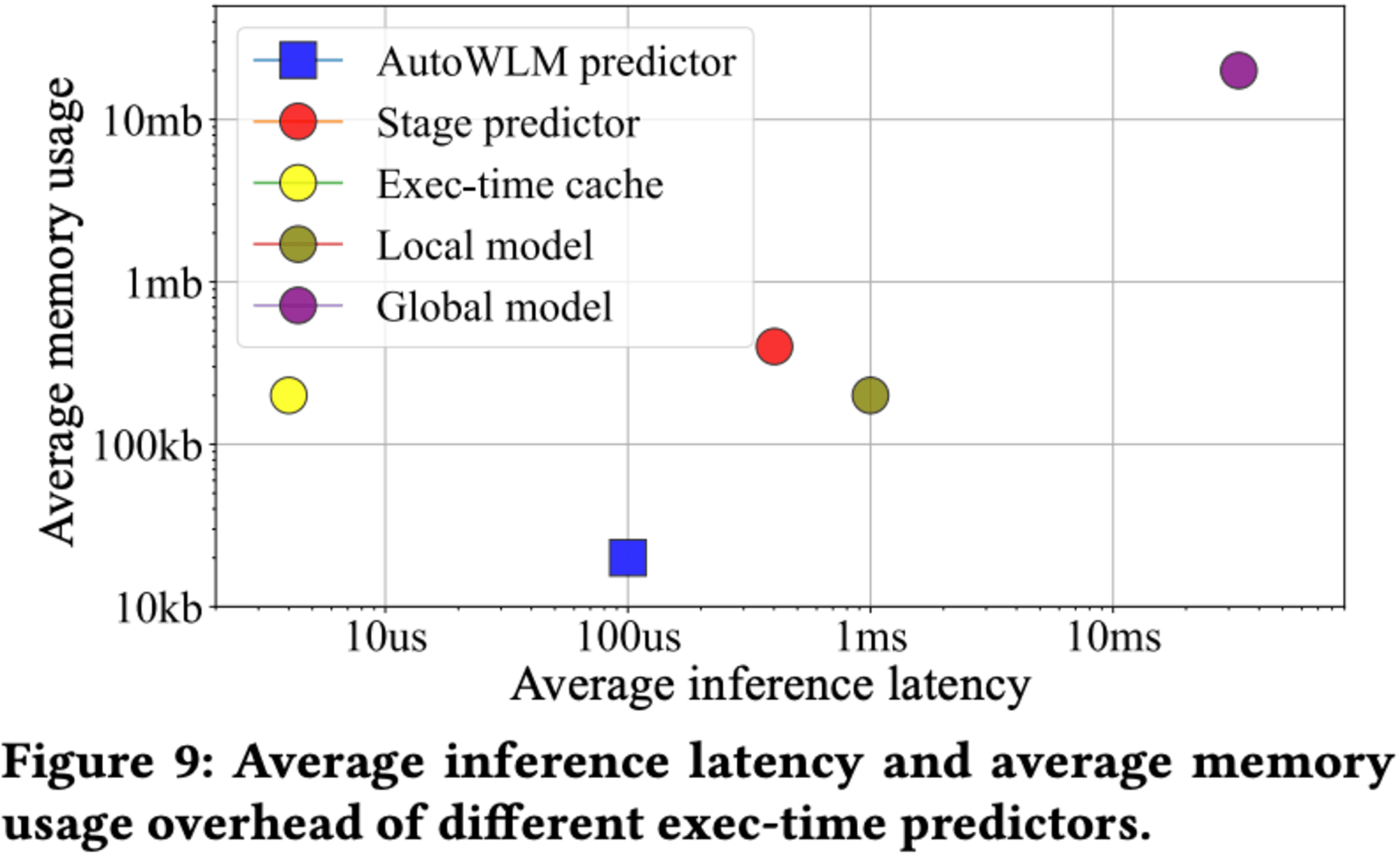
Stage Predictorの各コンポーネントの性能も示されており、実行時間キャッシュは数マイクロ秒で推論可能です。ローカルモデルはAutoWLM Predictorの10倍のサイズと遅延がありますが、グローバルモデルは深層学習ベースで最も大きいものの、使用頻度が低いため全体の性能への影響は限定的です。
今後の課題として、システム統計を考慮したより精度の高い実行時間予測器の開発が挙げられています。これにより、ラベルのばらつきを説明し、より正確な予測が可能になると期待されています。
5.4 Ablation study
データベースクエリの実行時間予測に関する研究の詳細な分析結果として、主に3つの予測モデル(実行時間キャッシュ、ローカルモデル、グローバルモデル)の精度と、ローカルモデルの不確実性測定の信頼性について解説します。
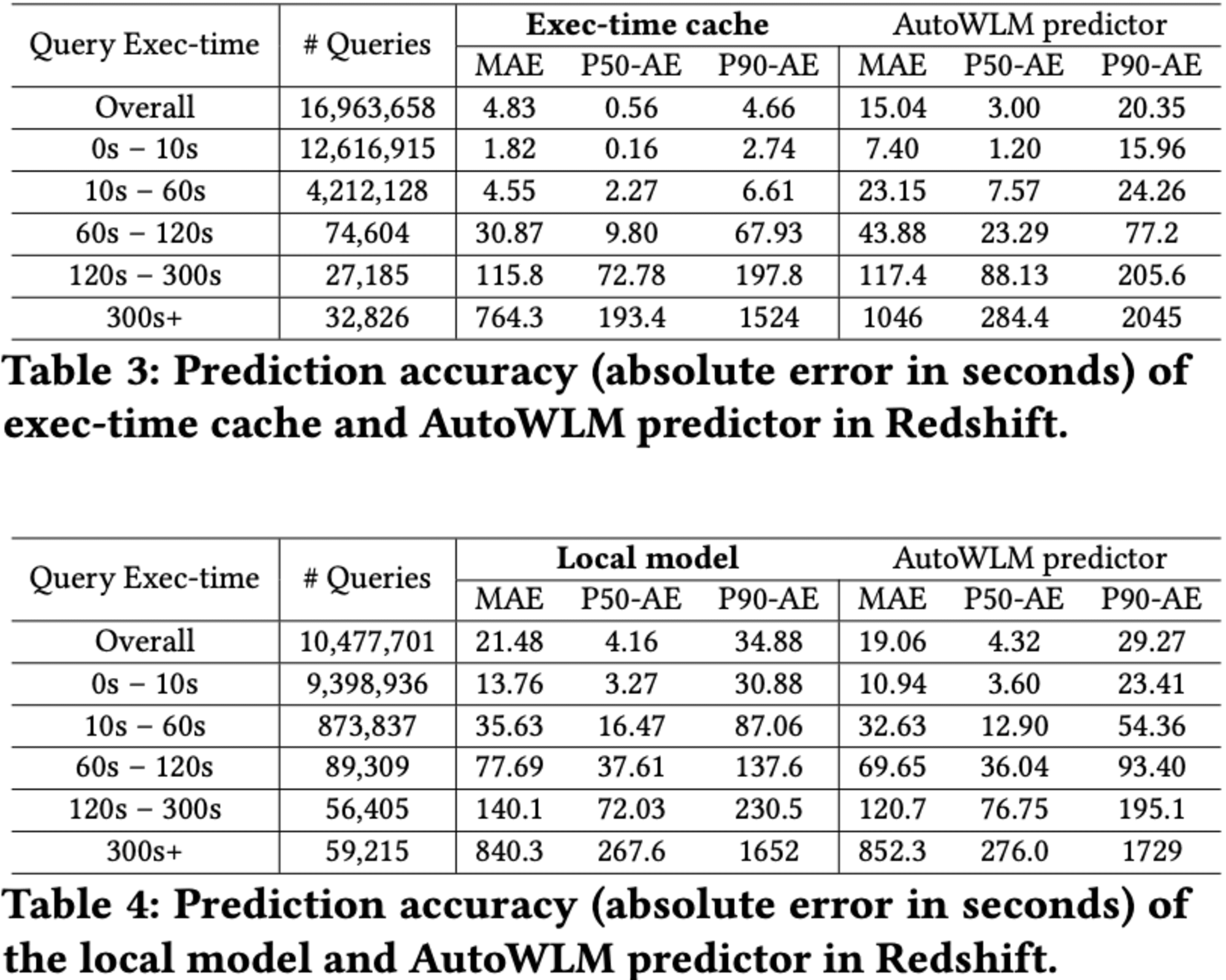
実行時間キャッシュは、全クエリの61.8%を占める繰り返しクエリに対して高い精度を示しました。しかし、システム負荷やバッファプールの状態、同時実行条件の違いにより、大きな誤差も発生しています。
ローカルモデルは、キャッシュにヒットしなかった38.2%のクエリに対して評価されました。AutoWLM Predictorと比較してわずかに劣る結果となりましたが、これは評価指標の違いによるものです。
Ablation studyは、多様なインスタンスで訓練され、未知のクエリに対して評価されました。予想に反して、ローカルモデルの方が全体的に優れた性能を示しました。これは、「より多くのデータがより良いモデルを作る」という一般的な考えに反する結果でした。
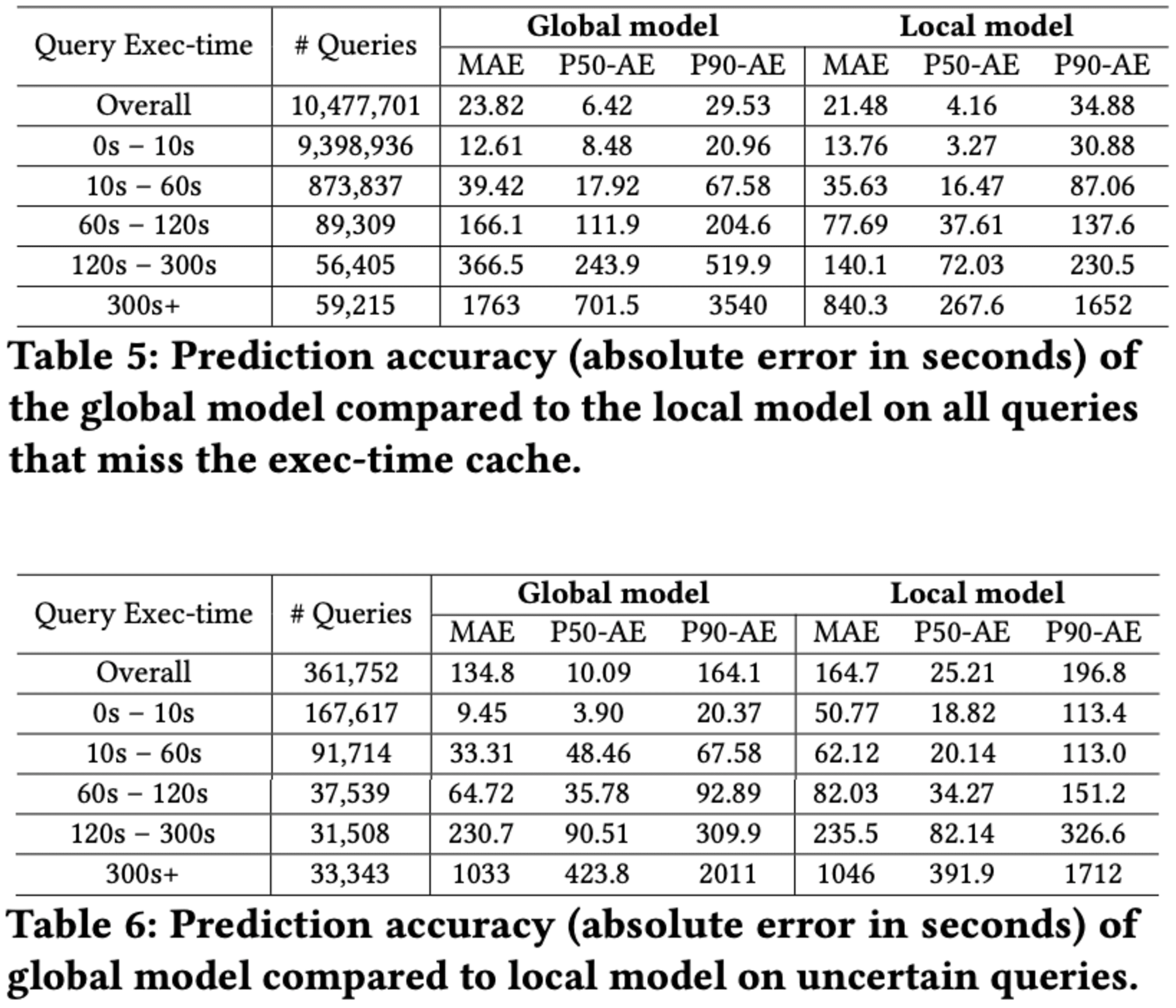
ローカルモデルが不確実と判断した長時間実行クエリに対しては、グローバルモデルがより信頼性の高い予測を提供できることが示されました。しかし、120秒以上の長時間クエリに対しては、インスタンス固有の特性があるため、グローバルモデルの改善はほとんど見られませんでした。
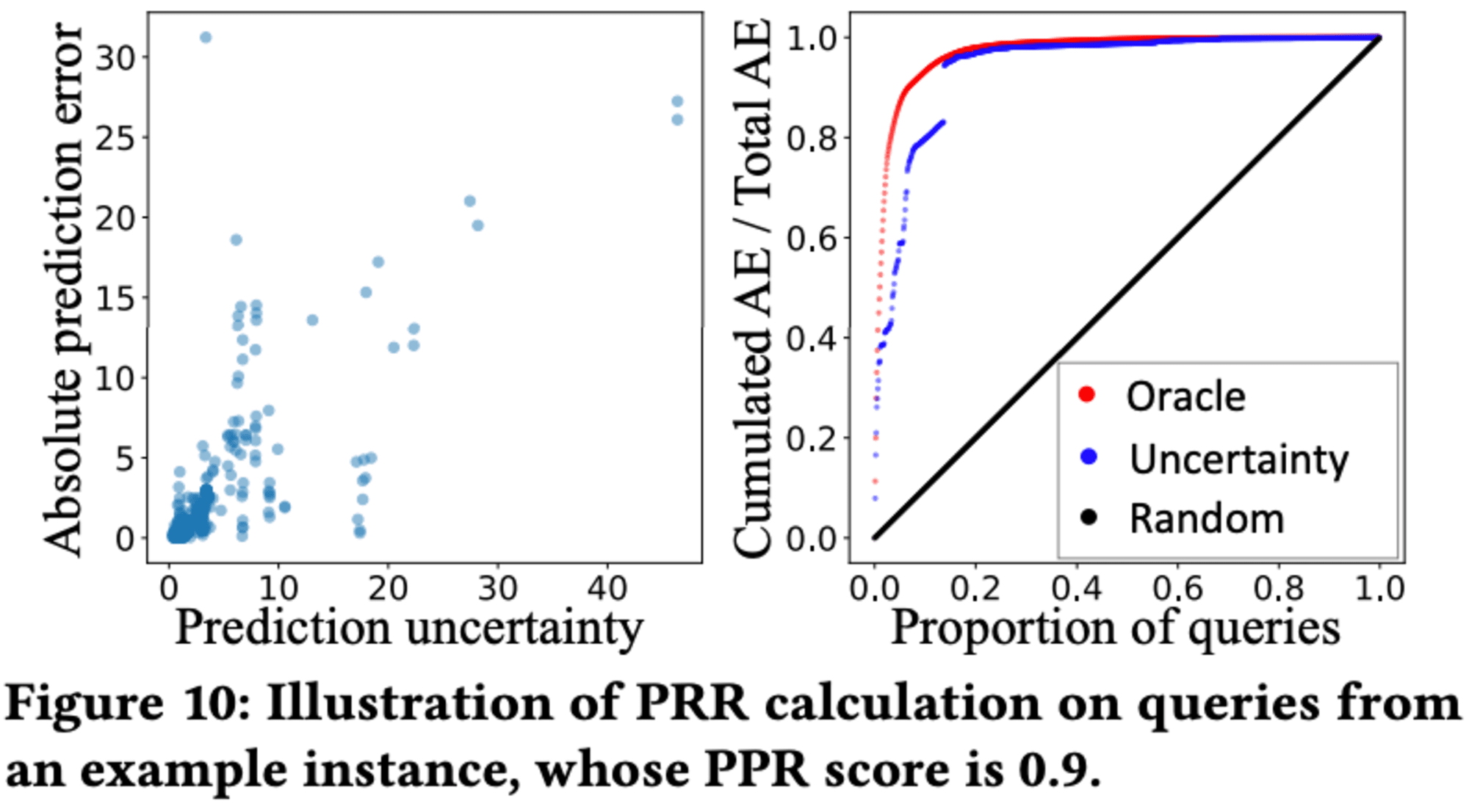
ローカルモデルの不確実性測定の信頼性は、予測拒否率(PRR)を用いて評価されました。多くのインスタンスで高いPRRスコアが得られ、不確実性測定が予測誤差を適切に捉えていることが示されました。ただし、一部のインスタンスでは訓練データ不足により低いスコアとなりました。
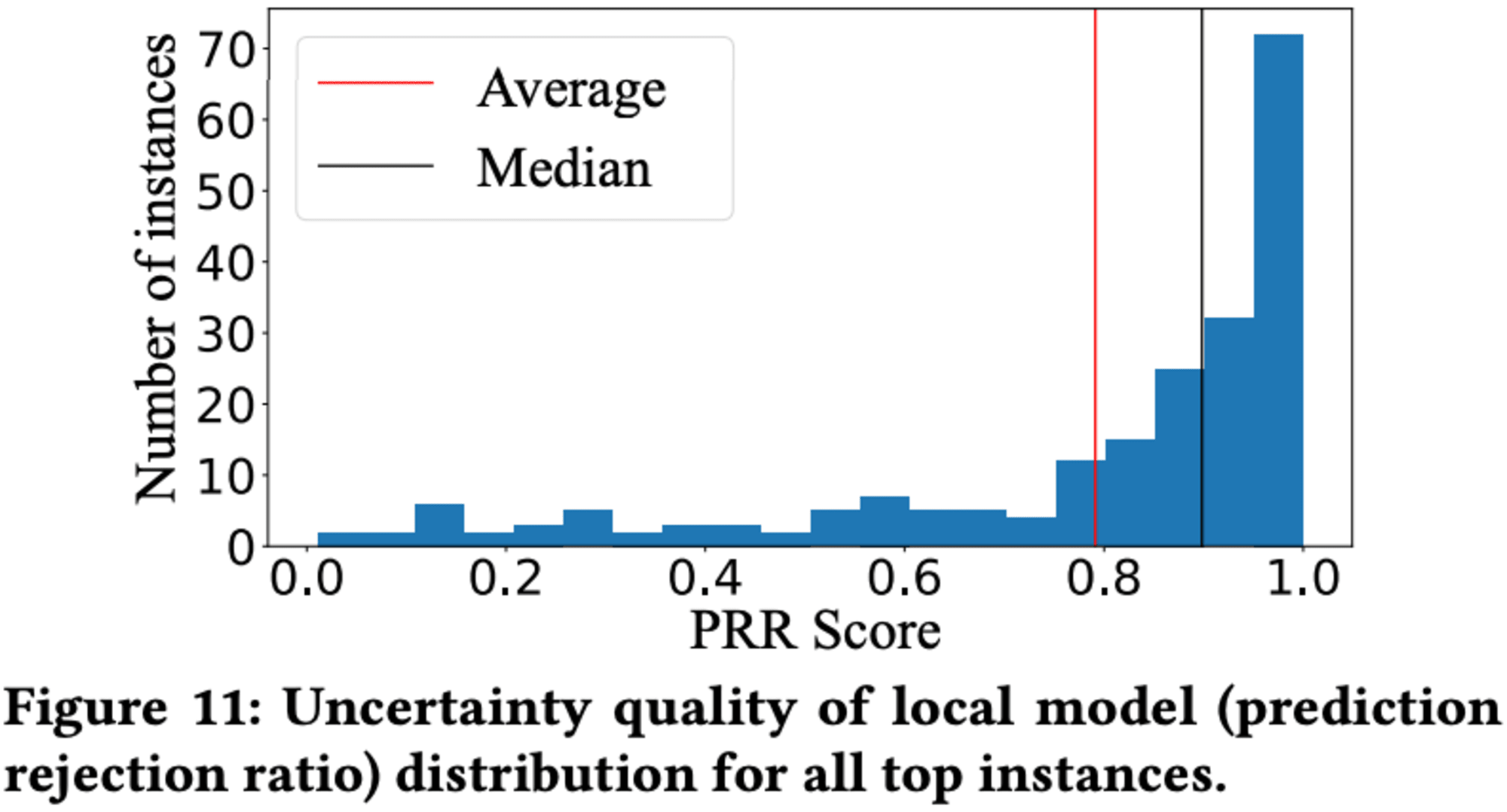
この研究結果は、クエリ実行時間予測において、インスタンス最適化モデルがクロスカスタマーモデルよりも効果的である可能性を示唆しています。また、グローバルモデルの性能向上には、データベース固有の特徴が必要かもしれません。今後の課題として、ローカルモデルとグローバルモデルの性能差を縮めるための改善が挙げられています。
6 LESSONS LEARNED AND POTENTIAL FUTURE RESEARCH DIRECTIONS
6.1 Applying Stage predictor in other tasks
Stage predictorは、Redshiftのワークロード管理の改善だけでなく、スマートDBMSにおける多くのタスクに新たな解決策をもたらす可能性があります。特に、クエリ最適化と仮説的推論において有用です。クエリ最適化では、Stage predictorをサブルーチンとして使用することで、ML基盤の最適化技術を実用的に統合できます。また、「what-if」質問への回答においても、Stage predictorのグローバルモデルは、より正確で詳細な答えを提供できる可能性があります。これは、他の類似データベースでの観察を活用して、現在のデータベースの仮説的シナリオ下でのクエリパフォーマンスを予測できるためです。
6.2 Hierarchical models
Redshiftの実用的な実行時間予測器を設計する際、機械学習ベースの予測器は高精度であるものの、推論オーバーヘッドが大きすぎるため、Redshiftのクリティカルパスへの導入が困難であることが判明しました。この問題は、実行時間予測やRedshift以外のデータベース研究コミュニティ全般にも存在すると考えられます。
機械学習モデルは一般的に、精度とモデルサイズ/推論レイテンシーの間にトレードオフがあり、より正確なモデルほどコストがかかる傾向があります。そのため、クエリ実行のクリティカルパスにおける既存のデータベース問題を解決するために高度な機械学習ベースのソリューションを採用すると、無視できないオーバーヘッドが発生し、短時間で実行されるクエリには負担が大きくなる可能性があります。
この問題に対して、階層モデルソリューションが実用的な解決策となる可能性があります。階層モデルを使用することで、機械学習ベースのソリューションの精度を最大限に活用しつつ、許容可能な推論オーバーヘッドを実現できると考えられます。例えば、カーディナリティ推定においても、複数の推定器を階層的に組み合わせることで、高精度な機械学習ベースのソリューションを実システムに統合することが可能になるかもしれません。
6.3 Environment factors in exec-time prediction
Redshiftにおいて、同じクエリを同じクラスタで実行しても、実行時のメモリやCPU使用率などの環境要因により、数秒から数分、数時間と大きく実行時間が異なることがある。例えば、メモリの90%が他のジョブで使用されている場合、クエリは中間結果をディスクにスピルし、大きなコストが発生する。しかし、実行時のメモリやCPU使用率を単に予測器の特徴量に加えても、クエリの実行中に変動するため、予測精度の向上は期待できない。さらに、キャッシュ効果やバッファプールの状態など、Stage Predictorやその他の実行時間予測器で特徴量化するのが容易ではない環境要因も存在する。これらの環境要因を正確に考慮できる実行時間予測器の設計が、予測精度のさらなる向上につながると考えられる。
7 CONCLUSIONS
Stage Predictor は、Amazon Redshift の特定の要件に合わせて設計された革新的な階層型クエリパフォーマンス予測ツールです。このツールは、分析ワークロードの反復的な性質を活用し、一般的で頻繁に発行されるクエリの待機時間を記憶することで、迅速かつ堅牢なクエリパフォーマンス予測を提供します。さらに、類似クエリと新規クエリに対して異なる2つの機械学習モデルを使用することで、予測の精度を高めています。Stage 予測ツールは、Redshift の以前の実行時間予測ツールと比較して、平均クエリ待機時間を20%改善することが示されました。 この開発過程で得られた知見に基づき、今後の研究の方向性についても示唆されています。
最後に
この論文は、Amazon Redshiftにおける新しいクエリ実行時間予測システム「Stage predictor」について説明しています。Stage predictorは、3つの階層モデルである、実行時間キャッシュ、インスタンス最適化されたローカルモデル、そして転移可能なグローバルモデルです。
現在のAutoWLM Predictorは、Stage predictor の一部(実行時間キャッシュとローカルモデル(XGBoost版))として既に本番環境でデプロイされていますが、新しいStage predictorは、平均クエリ実行レイテンシーを20%改善し、予測精度が2倍以上向上したことが示されています。
Stage predictorは、近年のゼロショットコストモデルの研究に触発されたり、ローカルモデルがXGBoostからXGBoostモデルのベイジアンアンサンブルに改善点する点など、心が惹かれました。また、Stage predictorは「60秒を超える長時間実行クエリに対しては、改善が限定的」という考察がありましたが、Stage predictorの導入によってAutoMVの精度向上が期待できるのであれば、AutoMVによって60秒を超える長時間実行クエリの頻度が限定的になるのではないかと考えました。今年のre:Invent 2024が楽しみです。










